Authors: Constanza Fierro, Jorge Perez, and Javier Mora
Year: 2020
Original Abstract: Deep learning techniques have been successfully applied to predict unplanned readmissions of patients in medical centers. The training data for these models is usually based on historical medical records that contain a significant amount of free-text from admission reports, referrals, exam notes, etc. Most of the models proposed so far are tailored to English text data and assume that electronic medical records follow standards common in developed countries. These two characteristics make them difficult to apply in developing countries that do not necessarily follow international standards for registering patient information, or that store text information in languages other than English.
In this paper, we propose a deep learning architecture for predicting unplanned readmissions that consumes data that is significantly less structured compared with previous models in the literature. We use it to present the first results for this task in a large clinical dataset that mainly contains Spanish text data. The dataset is composed of almost 10 years of records in a Chilean medical center. On this dataset, our model achieves results that are comparable to some of the most recent results obtained in US medical centers for the same task (0.76 AUROC).
Research question: How can we build a model for predicting unplanned readmissions within 30 days after discharge with Spanish text data without using Electronic Health Records (EHR) standards like FHIR or NCBO?
Reasons for the study: Studies have shown that unplanned readmissions are frequent (15% of annual hospitalizations in the US between 2013 and 2016) and expensive (cost of $17.6 billion in 2004 in the US). That’s why predicting unplanned readmissions can help to solve these problems.
Data: Historical data from Clinica Las Condes (CLC) records between November 2009 and December 2018. The data contains three main entities: Person, Problem, and Encounter. Person corresponds to personal data such as birth date, nationality, and sex. Problem corresponds to chronic illnesses or medical conditions that have lasted for a long period of time (eg. asthma). Encounter corresponds to one-time visit information such as beginning and end date, reason of the visit, and type of the visit. In addition, Encounter may contain 4 sub-entities: Diagnosis, Order, Clinical Note, and Form. Diagnosis corresponds to the details of the diseases diagnosed in that encounter. Order corresponds to medical exams orders or prescription drugs. Clinical Note corresponds to free text for any type of information that a doctor wants to add. Finally, Form is a list of key-value pairs that contain different types of information such as the description of patient state when she arrived at the emergency room, or measurements of the vital signs of an inpatient.
Method:
Definition of valid admissions: the patient didn’t die, the patient wasn’t discharged against medical advice, and the patient was not transferred to another hospital.
Definition of unplanned readmissions: every admission that does not have a pre-registration and every admission that has a pre-registration during the 24 hours before the hospitalization is created.
Creation of training dataset: each example has all the available patient history until a valid admission. It is labeled as 1 if the patient has an unplanned re-admission after 30 days of discharge, and 0 otherwise. Then, split the train (80%), validation (10%) and test (10%) sets by patient and not by example.

EHR representation: each entity data and each of their subentities and labels are considered as features. For example, two features are “order.medication.categorical_text” and “clinical note.content.text”. Each of these features can be associated with several different tokens. For example, tokens can be “levetiracetam”, “clonazepam” and “enalapril”, or, in the case of free text, the text “patient arrived with injuries”, is converted to the tokens “patient”, “arrived”, “with”, and “injuries”. In the case of the Form entity, a key-value pair is represented as (K_list, V_list), where K_list and V_list are lists of token ids for key and values. Finally, each patient history is represented as a list of timestamp-entities set of pairs.
Model: Embeddings were used to represent features and tokens. For each feature, a weighted average of token embeddings was calculated within a time window of 12 hours. For the Form entity, first, an element-wise mean of keys and values embeddings was calculated and then concatenated, later a weighted average was calculated as same as for the non-Form entities. For time window representation, the previously averaged embeddings were concatenated and a time embedding representing time with regard to the time of discharge (xt) is added (see figure below). Finally, the complete history is a sequence of time window representations.
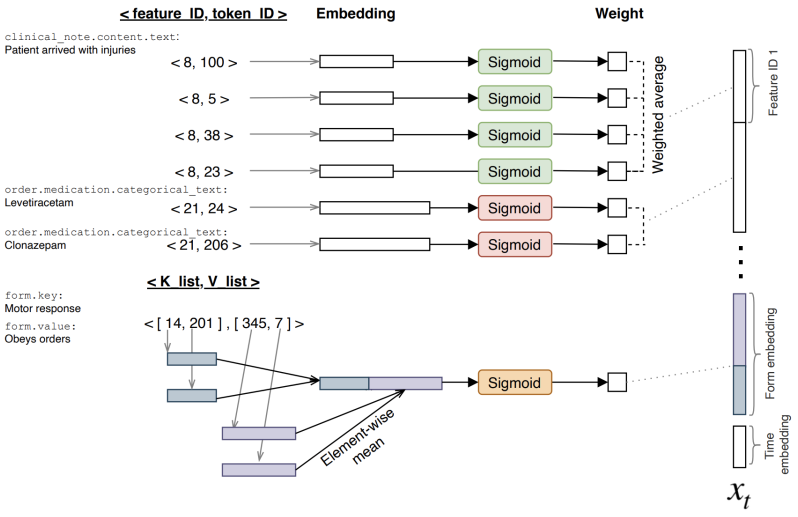
To make a prediction, an LSTM was fed with patient history. The last hidden state of the LSTM was used to perform a logistic regression to predict the probability for each class (0 or 1). The LSTM, the embeddings and weighted averages were optimized jointly to minimize the log-loss of the logistic regression using the Adam optimizer. Embedding dropout and LSTM hidden dropout were used.
Baseline model: TF-IDF of tokens of EHR representation, selection of 5000 tokens, and then a logistic regression to make a prediction.
Results: LSTM model was trained for 6 epochs, and the baseline model was trained for 8 epochs. Oversampling of positive examples was tried to reach 20% on the training set, but the results didn’t improve significantly (see table below).

Discussion: Comparable results with state of the art for English (Rajkomar et al., 2018). Low Recall for the class of interest is problematic in a real environment. First experience with Spanish data. As future work, recall can be improved and visualizations will help to understand what the model is focusing on.